

Introduction
AI 3D object generation is the process of utilizing powerful artificial intelligence tools to create and visualize 3D models in a more accurate, accessible, and efficient manner. These tools empower individuals from various backgrounds, including graphic designers and game developers, to bring their ideas to life in three dimensions by crafting models from scratch or using existing images, text descriptions, or even video footage.
The field of 3D modeling has seen significant advances in recent years thanks to a collective convergence of innovative techniques. This Blog explores the potential of combining three distinct but complementary approaches: Neural Radiation Fields (Nerf), photogrammetry and RealityKit, to create flexible and engaging 3D models.
Nerf, an advanced machine learning technique, enables the creation of photorealistic 3D models from collections of 2D images. Its power lies in its ability to capture complex details and geometries, often far beyond the capabilities of traditional methods.
Photogrammetry, a well-established method, uses a series of photographs taken from different perspectives to reconstruct 3D images of objects or scenes. This technique provides a practical and effective solution for creating accurate 3D models, especially for objects where physical representations are easily accessible.
RealityKit, a framework developed specifically for Apple’s ARKit platform, provides a streamlined workflow for creating and integrating 3D content into extended reality experiences. Its ease of use and optimization for XR applications make it a valuable tool for developers looking to deploy 3D models in immersive environments.
By combining these approaches strategically, we can leverage the unique strengths of each technique to overcome limitations and open new possibilities in creating High Quality 3D models. This blog examines the individual contributions of Nerf, Photogrammetry, and RealityKit.
Neural Radiation Fields (Nerf ): Transforming Images into 3D Worlds
NeRFs use neural networks to represent and render realistic 3D scenes based on an input collection of 2D images.
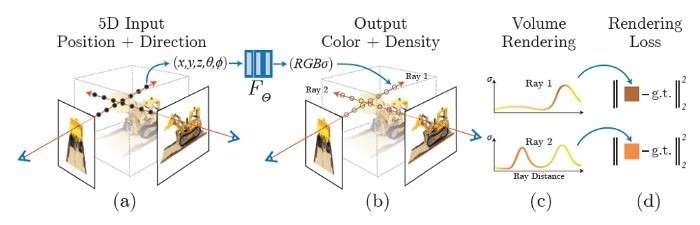
A neural radiance field (Nerf) is a fully connected neural network that can generate novel views of complex 3D scenes, based on a partial set of 2D images. Nerf takes a set of 2D images of a scene captured from different viewpoints as input. It utilizes a neural network to learn the relationship between a 3D point in the scene, its viewing direction, and the resulting color and density. Once trained, the network can predict the color and opacity (density) for any given point in the scene along a specific viewing direction. By combining these predictions for various points along virtual rays cast from a desired viewpoint, Nerf can render a new image of the scene from any novel viewpoint.
Nerf fundamentally leverages the concept of radiance fields in computer graphics. A radiance field is a function that defines the amount of light emitted from a particular point in space along a particular direction. Mathematically, a 5D radiance field is expressed as:

The core innovation of Nerf lies in the approximation of this radiance field using a fully connected neural network (multi-layer perceptron or MLP). The network effectively learns a mapping from the input coordinates and viewing direction to the corresponding color and density:
Network (x, d) ≈ F(x, d) = (c, σ)
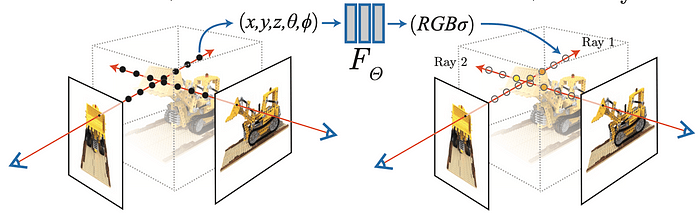
How Neural Radiance Fields Work
Neural Radiance Fields (Nerf) revolutionize 3D scene representation by leveraging a deep learning framework to learn a continuous volumetric scene function. This function empowers Nerf to generate novel views of a scene from a mere sparse set of input images.
Mathematical Representation:
Its inputs are:
- 3D location: x = (x, y, z) representing a specific point in space.
- 2D viewing direction: (θ, Φ) representing the direction from which the scene is observed.
Its outputs are:
- Emitted color: c = (r, g, b) representing the color emitted from the point in the specified viewing direction.
- Volume density: α representing the “opacity” or “thickness” of the scene at that point, influencing light attenuation.
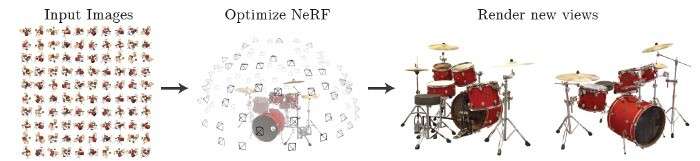
Here is how you can generate a Nerf from a specific viewpoint:
Point Sampling: Generate a sampled set of 3D points by casting camera rays through the scene. This involves systematically selecting points within the three-dimensional space, typically achieved through techniques like ray marching.
Neural Network Input: Input the sampled 3D points, along with their corresponding 2D viewing directions, into a neural network. The neural network is designed to map these inputs to output sets comprising densities and colors, effectively learning the volumetric characteristics of the scene.
Volume Rendering: Accumulate the obtained densities and colors into a two-dimensional image using classical volume rendering techniques. This involves combining the information derived from the 3D points to create a coherent and visually representative 2D image of the scene.
NVIDIA Instant NGP (Neural Graphics Primitives)
A team of researchers from NVIDIA, including Thomas Muller, Alex Evans, Christoph Schied, and Alexander Keller, showcased a novel methodology aimed at optimizing the effective utilization of artificial neural networks for computer graphics rendering. With “Instant Neural Graphics Primitives” (Instant-NGP), the research group shows a framework with which a neural network can learn representations of gigapixel images, 3D objects, and Nerf’s within seconds. You can view the full detail here .
The Github project have scripts/colmap2nerf.py, that can be used to process a video file or sequence of images, You can also generate camera data from Record3D (based on ARKit) using the scripts/record3d2nerf.py script.
I will cover a couple of key tips to help you compile the codebase and explain how to capture good input imagery. I walk through the GUI interface and explain how to optimize your scene parameters.
Requirements:
1. Python version 3.9
2. Visual studio community 2019
3. CUDA v11.6
4. Optix 7.3 or higher
5. COLMAP v3.7
For create dataset of image you can refer this video How to Capture Images for 3D Reconstruction – Computer Vision Decoded Ep. 5
Compiling the codebase
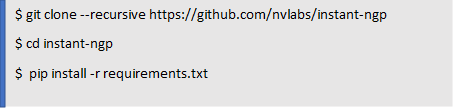
Begin by cloning this repository and all its submodules using the following command:
Then, use CMake to build the project: (on Windows, this must be in a developer command prompt)

If the build succeeds, you can now run the code.
If you are training from a video file, run the scripts/colmap2nerf.py script from the folder containing the video, with the following recommended parameters:
data-folder$ python [path-to-instant-ngp]/scripts/colmap2nerf.py –video_in –video_fps 2 –run_colmap –aabb_scale 32
For training from images, place them in a subfolder called images and then use suitable options such as the ones below:
data-folder$ python [path-to-instant-ngp]/scripts/colmap2nerf.py –colmap_matcher exhaustive –run_colmap –aabb_scale 32
you can now train your Nerf model as follows, starting in the instant-ngp folder:
instant-ngp$ ./instant-ngp [path to training data folder containing transforms.json]
Here is demo video of instant ngp :
Photogrammetry
Have you ever considered the possibility of transforming everyday photos into three-dimensional models? That is what exactly photogrammetry does. Imagine it as a digital jigsaw puzzle, where each photograph fragment contributes to creating a complete 3D representation of an object or even an entire scene.
But what exactly is this term “photogrammetry“?
“The word originates from a combination of “photo,” meaning “picture,” and “grammetry,” meaning “measurement.”
Essentially, it’s a technique for extracting valuable information like lengths, areas, and even volumes, all from ordinary photographs.
Meshroom
Meshroom is an open-source photogrammetry pipeline that allows you to create 3D models from a set of 2D images. It is a powerful tool that can be used for a variety of applications, including:
- Creating 3D models of objects for 3D printing
- Generating 3D models for use in virtual reality (VR) and augmented reality (AR) applications
- Creating 3D models for use in games and other visual media
Requirements:
- Windows x64, Linux, macOS (some work required)
- Recent Intel or AMD CPUs
- 8 GB
- ~400 MB for Meshroom + space for your data
How Meshroom Works
The Meshroom photogrammetry pipeline is a complex process, but it can be broken down into a few basic steps:
Preparing your images: The first step is to collect a set of images of the object you want to model. The images should be taken from a variety of angles and distances, and they should be well lit and in focus.
Feature extraction: Meshroom will then extract features from your images. These features are points of interest that can be used to match the images together.

Image Matching: Meshroom will then match the features in your images to create a sparse point cloud. A point cloud is a collection of points in 3D space.

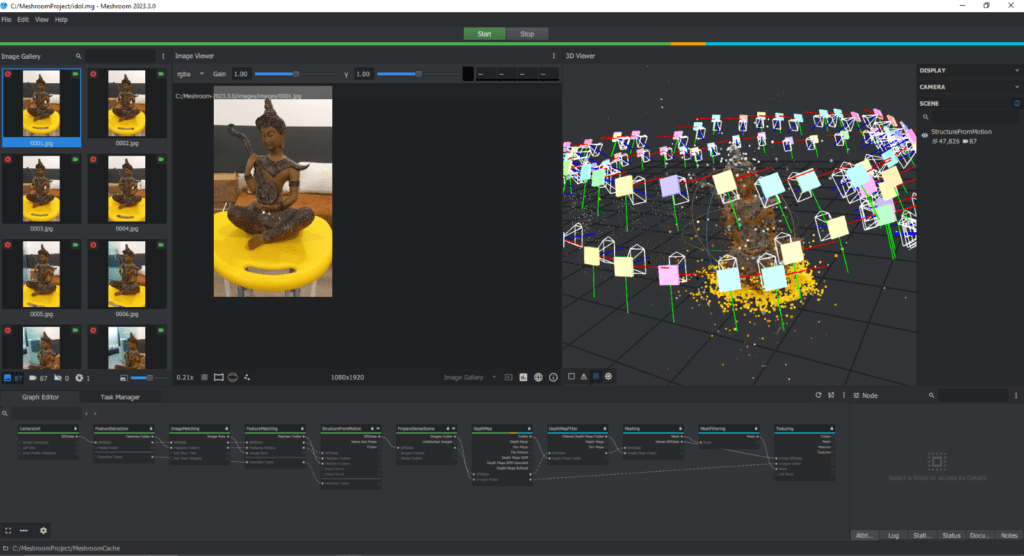
Structure from Motion (SfM): Meshroom will then use the sparse point cloud to estimate the camera positions for each of your images. This process is known as Structure from Motion (SfM). First, it fuses all feature matches between image pairs into tracks. Each track is supposed to represent a point in space, visible from multiple cameras. Then, the incremental algorithm must choose the best initial image pair. Then we compute the fundamental matrix between these 2 images and consider that the first one is the origin of the coordinate system. Now that we know the pose of the 2 first cameras, we can triangulate the corresponding 2D features into 3D points. Based on these 2D-3D associations it performs the resectioning of each of these new cameras. The resectioning is a Perspective-n-Point algorithm (PnP) in a RANSAC framework to find the pose of the camera that validates most of the feature’s associations. From these new cameras poses, some tracks become visible by 2 or more resected cameras, and it triangulates them. Then, we launch a Bundle Adjustment to refine everything: extrinsic and intrinsics parameters of all cameras as well as the position of all 3D points.
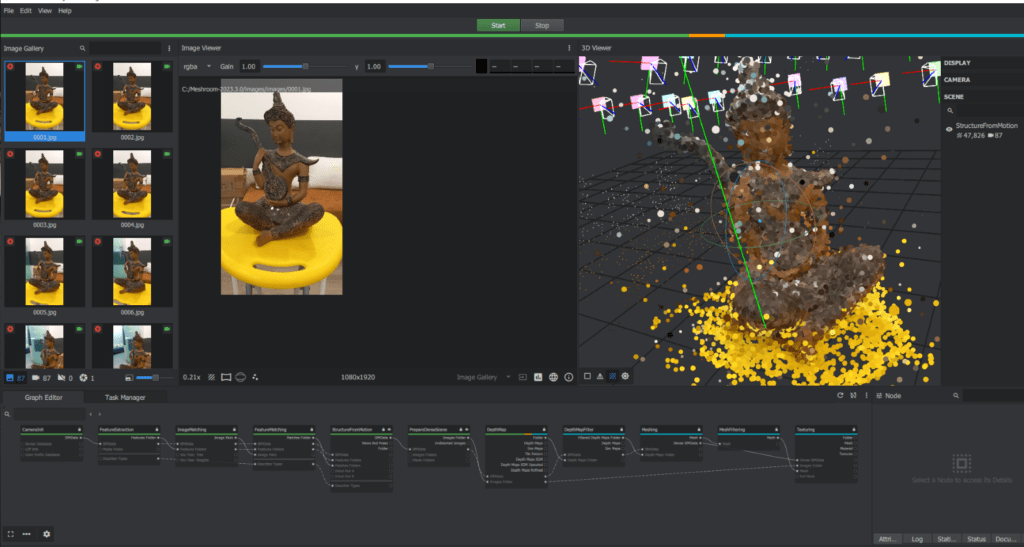
Depth: Meshroom will retrieve the depth value of each pixel for all cameras that have been resolved by SfM. It uses Semi-Global Matching (SGM) for generating the volume (H, W, Z) using SFM Output.
Meshing: Meshroom will then create a mesh from the dense point cloud and depth map. A mesh is a collection of polygons that defines the shape of the 3D model.
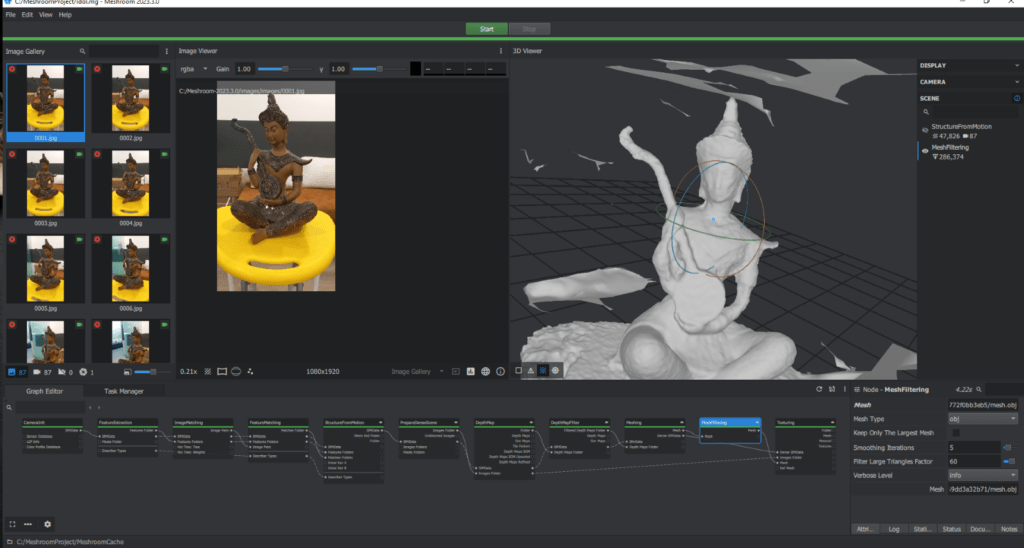
Texturing: Meshroom will then use the images to create a texture for the 3D model. The texture is a map that defines the color and appearance of the model’s surface.
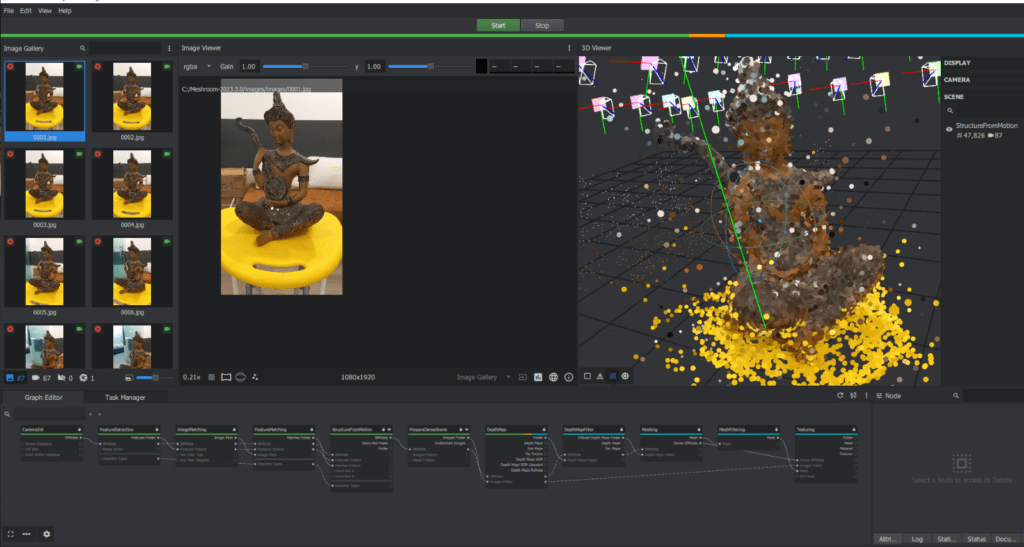
Exporting: Finally, you can export the 3D model in a variety of formats, such as OBJ, PLY, and STL.
RealityKit: Unleashing Augmented Reality Experiences on Apple Devices
Introduction
RealityKit is Apple’s framework for building captivating, augmented reality (AR) experiences on iOS, iPadOS, and macOS. It empowers developers to seamlessly integrate virtual objects into the real world, creating immersive and interactive applications. RealityKit leverages the power of Apple’s ARKit to accurately track the physical environment and seamlessly blend virtual content with it.

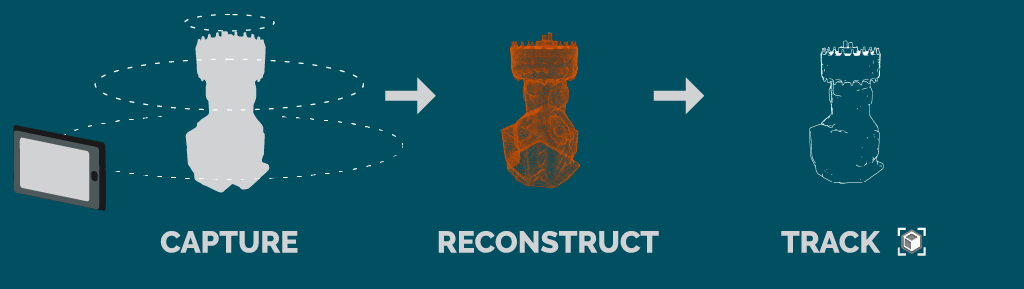
- RealityKit Object Capture: Democratizing 3D Content Creation on Apple Devices
- Apple’s RealityKit Object Capture API presents a powerful tool for effortlessly generating 3D models from real-world objects directly on iPhones and iPads. This technology empowers developers and creators to leverage the ubiquity of these mobile devices to bridge the physical and digital realms, fostering innovation and expanding the boundaries of 3D content creation.
Leveraging Photogrammetry:
The API employs photogrammetry, a well-established computer vision technique, to reconstruct 3D object geometry from a series of photographs. Users capture images of the target object from various angles, ensuring adequate lighting and minimal occlusion. The API then analyzes the overlapping information within these images to estimate the object’s depth and surface characteristics, ultimately generating a triangulated mesh representation.
Beyond Basic Capture:
While the core functionality revolves around capturing 3D geometry, the Object Capture API goes a step further by optimizing the generated models for AR experiences. This optimization process includes:
- Mesh Simplification: Reducing the number of vertices and triangles in the mesh to ensure smooth performance within resource-constrained AR environments.
- Material Mapping: Assigning physically based materials (PBR) to the model, enabling realistic lighting and shading effects within AR scenes.
- Collision Mesh Generation: Creating a simplified collision mesh alongside the main model, facilitating accurate object interactions within AR applications.
- Unlocking Creative Potential:
The availability of high-quality 3D models generated through the Object Capture API opens doors for diverse creative endeavors:
- Augmented Reality Experiences: Seamless integration of captured objects into AR experiences, enabling applications like interactive learning tools, immersive product visualizations, or location-based AR games.
- 3D Printing: Transforming digital models into physical objects using 3D printing technologies, allowing for the creation of tangible replicas or prototypes.
- 3D Asset Sharing: Contributing to online 3D asset libraries, fostering collaboration and accelerating development cycles within the creative community.
- Technical Considerations:
- While the API offers a user-friendly experience, understanding the underlying technical aspects can further enhance its utilization:
- Photogrammetry Limitations: The accuracy and detail of captured models are influenced by factors like image quality, lighting conditions, and object complexity.
- Optimization Techniques: Advanced users can explore mesh optimization algorithms beyond the built-in functionalities to achieve a balance between model fidelity and performance.
- Integration with AR Frameworks: Integrating captured models with AR frameworks like ARKit requires additional considerations, such as proper anchor placement and collision handling.
- The Future of Object Capture:
- The Object Capture API represents a significant step towards democratizing 3D content creation. As technology evolves, we can expect further advancements in areas like:
- High-Fidelity Capture: Utilizing advanced computational photography techniques to capture finer details and textures of objects.
- Automated Material and Texture Assignment: Leveraging machine learning algorithms to automatically assign realistic materials and textures to captured models, reducing manual post-processing efforts.
- Real-time Object Scanning: Exploring the potential of LiDAR sensors and real-time processing for capturing dynamic objects or scenes.
Supported Devices:
- iOS: iPhone 8 and later, iPad Pro (2017 and later), iPad (5th generation and later), iPad Air (3rd generation and later), iPad mini (5th generation and later).
- iPadOS: Mirrors iOS device compatibility.
- macOS: Mac computers equipped with Apple silicon (M1 chip or later).
Hardware Requirements:
- ARKit Support: RealityKit builds upon ARKit, necessitating devices that support ARKit capabilities. This typically means a device equipped with a LiDAR scanner or a combination of a TrueDepth camera and a robust A-series or M-series chip.
Specific Features:
- Face Tracking: Requires a device with a TrueDepth camera, commonly found in recent iPhones and iPads.
- Body Tracking: Currently limited to iPhone XR and later models featuring an A12 Bionic chip or later.
- Object Scanning: Requires a LiDAR scanner, available in iPhone 12 Pro and Pro Max, iPad Pro (2020 and later), and newer models.
- Spatial Audio: Requires a device with support for spatial audio features.
Additional Considerations:
- Performance: The performance of your AR experience may fluctuate based on the device’s processing power and graphics capabilities. More intricate scenes and features may demand newer devices for optimal performance.
- Software Updates: Ensure your iOS, iPadOS, or macOS versions are up to date to access the latest RealityKit features and bug fixes.
Spatial Recognition and Light Bounce Capture:
For spatial recognition and accurate light bounce capture, Apple utilizes LiDAR technology. Let’s delve into how Apple’s LiDAR scanner works to capture 3D objects:
LiDAR Technology:
LiDAR, short for Light Detection and Ranging, is a remote sensing method akin to radar. However, instead of radio waves, LiDAR scanners in Apple devices emit light pulses, typically in the infrared spectrum.
Capturing Depth Information:
By measuring the time, it takes for the reflected light to return to the sensor, the LiDAR scanner calculates the distance to each point on the object’s surface. This process generates a point cloud, essentially a collection of 3D points representing the object’s surface.
Dense Point Clouds:
Unlike traditional cameras that capture color information, LiDAR scanners prioritize depth. Modern LiDAR scanners, like those in iPhones and iPads, produce dense point clouds, capturing numerous data points per unit area. This capability allows for a more accurate and detailed representation of the object’s shape.

Challenges and Considerations:
Lighting Impact: LiDAR scanners perform optimally in well-lit environments. Lower light conditions can compromise the accuracy and detail of the captured point cloud.
Transparent and Reflective Surfaces: Transparent objects like glass or reflective surfaces can pose challenges. Light pulses may pass through or reflect erratically, impacting the precision of data capture.
Advanced Techniques: Simultaneous Localization and Mapping (SLAM) is often employed in Apple devices. LiDAR data is combined with gyroscope and accelerometer information to enhance the understanding of the surroundings, crucial for AR applications.
Data Fusion: LiDAR data is sometimes merged with camera color information to enrich 3D models with texture and visual details.
Advanced Exploration:
Custom Shaders: Develop custom shaders for advanced visual effects and precise material adjustments.
Physics Simulations: Leverage RealityKit’s physics engine to simulate realistic interactions between virtual and real-world objects.
Machine Learning Integration: Incorporate Core ML models for tasks like object recognition, image segmentation, and real-time environmental understanding.
Spatial Audio: Integrate spatial audio for immersive soundscapes that adapt to user head movements and virtual object positions.
Multiplayer AR: Explore frameworks like RealityKit Networking for collaborative AR experiences, enabling multiple users to interact within the same virtual world.
How object capture API works:
Capturing the Object:
Image Acquisition: You take a series of photos of the object from various angles. The API recommends good lighting and avoiding harsh shadows or highlights for optimal results.
Data Extraction: Each image is analyzed to extract key information like color, texture, and potential overlapping areas with other photos.
3D Reconstruction using Photogrammetry:
Feature Matching: The API identifies and matches similar features (corners, edges, patterns) across the captured images. This helps establish corresponding points between photos.
Depth Estimation: Using the overlapping areas and known camera positions, the API estimates the depth information for each point in the scene. This creates a preliminary understanding of the object’s 3D structure.
Mesh Generation: Based on the extracted depth data and feature correspondences, a 3D mesh is constructed. This mesh represents the geometric shape of the captured object.
Optimization for AR Applications:
Mesh Simplification: The initial mesh might be complex, so the API simplifies it by reducing the number of vertices and triangles while preserving the overall shape. This ensures efficient rendering and smooth performance within AR experiences.
Material Mapping: The API assigns physically based materials (PBR) to the mesh. These materials define how light interacts with the object’s surface, leading to a more realistic appearance in AR scenes.
Collision Mesh Creation: An additional simplified collision mesh might be generated alongside the main model. This collision mesh is crucial for enabling interactions with the scanned object within your AR application.
Output and Integration:
The final product is a compact and optimized 3D model (USDZ file) suitable for AR integration. You can use this model directly within your ARKit-based applications or export it for further editing in 3D design software.

In conclusion, Reality Kit’s Object capture API empowers developers to craft engaging AR experiences for Apple devices. By grasping its core concepts, utilizing its tools and features, and exploring advanced topics, you can create innovative applications seamlessly blending the digital and physical realms. This documentation serves as a starting point for your journey, and as you delve deeper into RealityKit’s functionalities, a future of immersive virtual worlds awaits.
Comparison of 3D Reconstruction Tools: Instant NGP, Meshroom, and Reality Kit
Meshroom, Instant NGP, and Reality Kit (Object Capture Api) are all software tools used for 3D model generation, but they cater to different needs and have varying strengths and weaknesses. Here’s a comparison to help you choose the best option for your need:
Choosing the right tool for 3D reconstruction can be crucial for your project’s success. This comparison will analyze three popular options: Meshroom, Instant NGP, and Object Capture API (Reality Kit) to help you make an informed decision.
1. Technology and Approach:
Meshroom: Open-source software that employs a structure from motion (SfM) pipeline. It analyzes a set of images from different viewpoints to reconstruct the 3D geometry of the scene.
Instant NGP: Utilizes neural rendering techniques to generate 3D models from a single image or a small set of images. This approach is faster than SfM but may lead to less detailed or accurate reconstructions.
Object Capture API (Reality Kit): Apple’s framework specifically designed for iOS devices that leverages LiDAR scanners to capture high-fidelity 3D models of objects and environments. It offers a streamlined workflow but is limited to Apple devices with LiDAR scanners.
2. Input Requirements
Meshroom: Relies on a set of overlapping images captured from various angles around the subject. The quality and number of images significantly impact the reconstruction accuracy.
Instant NGP: Accepts limited set of images as input. While convenient, this approach may lead to less detailed or even inaccurate reconstructions for complex objects or scenes with occlusions.
Object Capture API (Reality Kit): Requires an Apple device equipped with a LiDAR scanner and focuses on capturing objects near the device. It is not suitable for capturing large environments or objects beyond the scanner’s range.
3. Reconstruction Quality:
Meshroom: Offers highly detailed and accurate reconstructions when provided with sufficient high-quality images. However, the process can be time-consuming
Instant NGP: Trades reconstruction quality for speed and ease of use. While it can generate 3D models rapidly, the details and accuracy may be inferior to Meshroom, especially for intricate objects or scenes with challenging lighting conditions.
Object Capture API (Reality Kit): Produces high-fidelity 3D models of objects with good detail and accuracy, leveraging the LiDAR scanner’s depth information. However, it is limited to capturing objects and is not suitable for reconstructing larger environments.
4. Ease of Use:
Meshroom: Has a steeper learning curve due to its open-source nature and simple to use with default pipeline but can be challenging when customizing the default pipeline for faster or better results
Instant NGP: Offers a user-friendly interface and requires minimal technical knowledge. Uploading images and generating the 3D model is a straightforward process.
Object Capture API (Reality Kit): Provides a simple and streamlined workflow designed specifically for Apple devices. However, it requires familiarity with Swift programming language and is limited to compatible devices.
5. Cost:
Meshroom: Completely free and open-source software.
Instant NGP: Offers a free tier with limited features and paid plans with increased functionality and processing quotas.
Object Capture API (Reality Kit): Available as part of the Xcode development tools, which are free to download and use. However, it requires an Apple device with a LiDAR scanner, which incurs additional hardware costs.
Conclusion:
The best choice among Meshroom, Instant NGP, and Object Capture API depends on your specific needs and priorities. Consider the following factors:
Reconstruction quality: If high accuracy and detail are crucial, Meshroom is the way to go, but be prepared for a steeper learning curve.
Ease of use: Instant NGP excels in simplicity and speed but be mindful of potential limitations in reconstruction quality.
Device compatibility: Object Capture API is the clear choice for capturing objects on Apple devices with LiDAR scanners, offering a user-friendly and high-fidelity solution within the Apple ecosystem.


