

Tables are information-rich structured objects. They are widely used to present compact and readable information in documents. However, it’s challenging to parse the scanned and digital documents (PDFs and images) and convert them into a machine-readable format for information extraction.
Much effort has gone into localizing the tables as graphic objects in the document images. However, there hasn’t been much progress on table structure recognition, as they are pretty tricky to read.
The existing research on structure recognition largely depends on these factors-
- The extraction of meta-features from the pdf documents
- Using the OCR model (Optical Character Recognition) on images to retrieve the low-level features
These methods lead us to ask –
- How precise are these methods?
- Can they extract information from complex tables?
Table Structure Recognition
Table Structure Recognition (TSR) aims to recognize the structure of a table and transform unstructured tables into a structured format. It would assist in the downstream tasks, such as semantic modeling and information retrieval.
It focuses on localizing and detecting each cell, row, and column present within a table. In TSR, seeing these cells, rows, and columns is equally vital as tables. The reason is that the entire table composition is needed to extract pertinent information.
How does Table Structure Recognition help in business?
Many industries, including banking and insurance, use tables in their documents to track the process and manage assets. While ordering online or purchasing offline in stores, your invoice comes out as a table. We see them often across several areas, from organizing our work by structuring data across the tables to storing huge assets of companies. The most burning use case of table extraction is from invoices, forms, bank statements, and documents containing tables used in day-to-day business workflows.
Thus, table extraction is a necessity for numerous business use cases:
Automated Invoice Extraction: Invoices present information in a tabular form, and its extraction is tedious. To address this, we can use table extraction to convert all invoices into an editable format and extract the information like the total cost, invoice date, invoice numbers, etc.
Bank Documents Automation: Banks present and process information in forms or tables. Due to the tediousness of this task, there is a high chance of human error. Using automation to extract the info saves time, making the process easy and fast.
Traditional Approaches
We used several methods and libraries to extract tables and information, including Excalibur, Camelot, and Regex parsing, along with the combinations of OCR with the document layout.
We experimented with the traditional approaches but couldn’t find any sustainable solution. The main challenges in conventional methods are-
- They can extract information from tables that use simple templates but cannot handle complex formats.
- Difficulties in adjusting the threshold values of tables as per the changes in the layout
- While using the regex parsing, sometimes noise is extracted as information.
- The OCR fails to distinguish the borders of cells and columns and merges the text.
- Muti page and spanning tables are hard to capture from traditional methods.
Our Recommendation
Deep Learning is the best option for table structure recognition. It has shown promising results in understanding the table layout and keeps improving over time.
TSR is a challenging problem due to its complex structures and high variability in the table layouts. Early attempts are dependent on meta-data features of PDFs over the rule-based algorithms. Some of these methods are domain-dependent and assisted by textual information. While the text features are helpful, visual analysis is crucial for complex document layouts. Here are a few challenges addressed by image-based models.
- Inconsistency in table size
- Location of table cell borders
- Variation in shapes
- Spanning of rows
- Multiline cells
Maneuver through Deep learning
Deep Learning is quite complex but depicts high performance in results in real-time. Some of the approaches are –
DeepTabStR
Deep Learning-based Table Structure Recognition
This method uses Table Structure Recognition as an object detection problem and leverages the potential of deformable convolution operation for the task.
It breaks down the problem by identifying the corresponding rows and columns and then coupling them to identify the cells.
Multi-Type-TD-TSR
Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition
This paper presents a multistage pipeline named Multi-Type-TD-TSR, which offers an end-to-end solution for the problem of table recognition. It utilizes state-of-the-art deep learning models for table detection and differentiates between 3 different types of tables based on the table’s borders. For table structure recognition, a deterministic non-data-driven algorithm is used, which works on all table types. Additionally, two algorithms, one for unbordered tables and one for bordered tables, are the base of the table structure recognition algorithm.
DeepDeSRT
Deep Learning for Detection and Structure Recognition of Tables in Document Images
DeepDeSRT is a Neural Network Framework that detects and understands the tables in documents or images.
- It is a deep learning-based solution for table detection in document images.
- It is a novel deep learning-based approach for table structure recognition, i.e., identifying rows, columns, and cell positions in the detected tables.
It is a data-based model and does not require heuristics or metadata of the documents or images. The concept of transfer learning and domain adaptation for both table detection and table structure recognition was used in this method.
Other methods are TableNet, Graph-Based TSR, etc.
Our Approach
We, at 47Billion, have an innovation lab where we tested and evaluated several frameworks and models available in deep learning. We designed the TSR system with several methods and combined them to achieve the end goal.
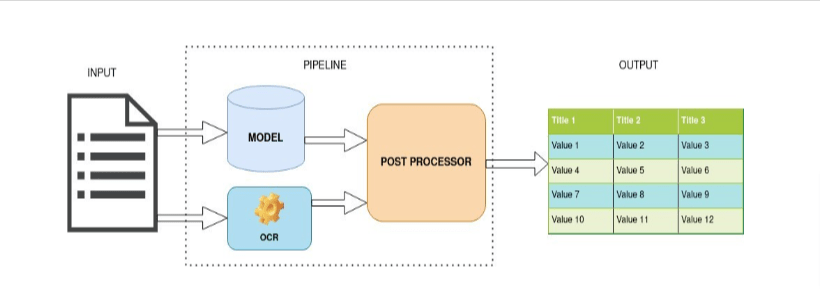
Data and Challenges
The data we used consists of PDFs and scanned images from various financial documents. We included different types of documents with tables spanned across multiple pages, divided into sections, multiline spanning cells, etc.
Some challenges that we faced challenges were data inconsistency and labeling cells. We also included open-source data to make our model robust and generalizable.
Data Pre-Processing
We used several techniques to handle noise present in data, such as-
- De-skewing of images
- Adaptive binarization
- Removal of noisy images
Development
When we developed this model, we ensured it needed a low memory. We plan to make it available directly through an application or an API.
We have experienced better results after running an end-to-end TSR pipeline on most financial documents, invoices, and similar documents.
Conclusion
- Model performance measured on financial documents, invoices, and open-source data yield better results.
- We tested on multiple models and recorded better performance with our solution.
- The combination of OCR and deep learning made the TSR pipeline robust and accurate.
- Visit https://47billion.com to know more.


