

This blog is the second part of my series of blogs “A brief introduction to AutoML Tools”. In the previous blog, I covered up everything about MLBox, so I recommend you to go through that blog first.
For comparison, I will be using the same dataset – Framingham Heart Study. It has a considerable amount of missing values which will give you an idea of how these tools handle missing values. The goal is to compare all the three tools based on the following:
-> Accuracy Achieved
-> Ease to understand and implement a score
-> Time taken to complete the task
In this blog, I will be sharing my experience of implementing GAMA.
A Brief Intro to GAMA:
GAMA – Genetic Automated Machine learning Assistant
According to the official documents of GAMA,
GAMA is a tool for Automated Machine Learning (AutoML). All you need to do is supply the data, and GAMA will automatically try to find a good machine learning pipeline. A machine learning pipeline contains data preprocessing (e.g. PCA, normalization) as well as a machine learning algorithm (e.g. Logistic Regression, Random Forests), with fine-tuned hyper-parameter settings (e.g. number of trees in a Random Forest). GAMA uses multiple search procedures to implement the pipeline and also combines multiple tuned machine learning pipelines into an ensemble, which on average should help model performance.
This takes away the knowledge and labor-intensive work of selecting the right algorithms and tuning their hyper-parameters yourself.
Installation:
Considering you already have pip, installing GAMA is very easy and straightforward. Just run the following line

Okay now let’s get started
Import packages:
GAMA, for now, provides AutoML for the following task:
- Binary Classification
- Multiclass Classification
- Regression
First, we need to import the library.

For both the classification task, we have to import the following package:

And for the regression task, we have to import the following package:

Other libraries to be imported:

Step 1: Getting the data and splitting it into train, test:
We need to manually import the data and split it into train and test data.

Step 2: Create an object of GAMAClassifier Class and fit the model
We need to create an object of GAMAClassifier Class and define the required parameters.
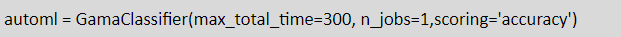
Parameters:
- max_total_time: Time in seconds that can be used for the fit call.
- scoring : Specifies the metrics to optimize.
- n_jobs : The number of parallel processes that may be created to speed up to fit.
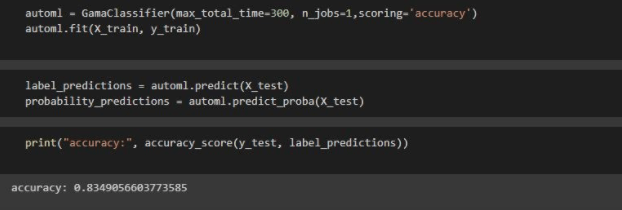
Now, we need to fit the model on the train data as shown below:

Step 3: Prediction
This is the step in which the model make predictions on the test data:

That’s it, you are done with GAMA. This is amazing right!!
Code Export(optional)
It is possible to have GAMA export the final model definition as a Python file

4) Conclusion on GAMA:
1) GAMA involves just 3 steps to complete the whole AutoML Pipeline.
2) The average taken for data preprocessing, hyper-parameter selection and training is 4 mins and 30 sec.
I used Google Colab to run this tool so results vary according to which system you are using.
3) The accuracy achieved in default configuration is 83%.
4) Ease to understand and implement score:
I will give this library 8/10 for ease to understand and implement. It is very simple to implement as it involves only 3 major steps. The official document provided is very easy to understand. It provides a detailed explanation of the API and also provides benchmark results of GAMA and other famous AutoML tools. Which is interesting to explore. But, you won’t find any good blogs regarding GAMA. So, the official document and this blog is the only way to go.
5) Pros and Cons of GAMA:
The pros are:
- Automatic task identification i.e. Classification(Binary,Multi) or Regression
- Very easy to implement with minimal lines of code.
- Achieves accuracy similar to other famous tools.
- Also provides its own dashboard (gamadash) which is not completely available but is functional to get some early feedback. GAMA Dashboard is a graphical user interface to start and monitor the AutoML search.
- Also provides visualization as a part of gamadash.
- Provides benchmarks of GAMA and other AutoML tools.
The cons are:
- It can only load csv and arff files for now.
- Still under development so cannot be used for production.
- Had to manually specify the task by importing GamaClassifier or GAMARegressor.
- Cannot be used for deep learning tasks like image classification or object detections or test prediction.
- Doesn’t show any information regarding what’s going on in the backend, unless we print it explicitly.
The next and final blog is about AutoGluon.


