

Every day mortgage processing companies, healthcare insurance companies, banks, finance, legal, HR departments, and government agencies review and extract data from millions of documents to make decisions. Some of these documents like Uniform Residential Loan Application (1003) or Appraisal forms (1004) for the US mortgages are standardized forms but others like Deeds, Bank Statements are semistructured or unstructured. Similarly, Electronic Health Records (EHR), Lab results, Invoices, Legal contracts, Resumes, etc. are completely unstructured and in nonstandard format.
The unstructured data in documents is not merely a byproduct of operations but a vital resource for actionable insights. The ability to extract value from unstructured data is what will separate businesses from their competition.
In this article, we discuss the challenges of managing unstructured data and how a data catalog can help organize and distribute such knowledge within the enterprise.
The proliferation of data in documents
Document imaging departments in all these companies employ thousands of workers reviewing documents and extracting data manually in excel sheets using the “stare and compare” method. This extracted data is later used for decision-making like loan approvals, medical coding, auditing, and compliance.
With an ever-increasing volume of such unstructured documents, document extraction operation has become a bottleneck, affecting the ability to make decisions quickly and respond to consumers and partners. For the mortgage industry, timelines for borrowing, servicing, processing, and underwriting are stretched resulting in long waits for borrowers. Also, due to such complexity and time involved in extraction operation, massive volumes of unstructured data in enterprises stay dormant and unused resulting in enterprises working in silos without interoperability.
Untrap data from documents — Document Understanding Products
Eliminating manual data entry is the first step towards solving these challenges. A new set of products is in the market that extracts structured data from unstructured documents. Using machine learning, these products automatically recognize and extract valuable business information from unstructured data. Due to the nature of unstructured data, the accuracy of extraction is never 100%. Depending on the tolerance to this accuracy level, these products provide a human-in-the-loop user interface to correct the inaccurately extracted data.
Challenges of unstructured data extraction
- Messy, scattered, and unorganized data
- Data teams spent preparing and tidying data instead of analyzing and reporting
- Quality Control teams that do manual correction on automated extracted data need training on all the different ways a particular attribute can be found in semistructured or unstructured documents
- Word-of-mouth knowledge as to where the data resides within a document
- Numerous and diverse data spread across different document types
- Single document types like invoice can have multiple formats depending on the originator
- Difficult for employees to trust any information so they do not use data outside their sphere of knowledge, fearing they may accidentally use incorrect or outdated information
What is Data Catalog?
For companies to truly become data-driven, data discovery and catalog solutions are essential to be used for analysis and reporting. The data catalog allow users to answers questions like –
- Where is the data?
- How did this data get here?
- What does this data describe?
- What is the use of this data?
- Who is the owner of this data?
- How is the data being transformed?
- Who has visibility to what data?
Data catalog
- Provides a common business vocabulary across the organization for technology and business teams
- Documents reusable knowledge of data assets
- Saves time and effort on finding and accessing relevant data
- Tracks data usage and commonly accessed data
- Allows publishing data to the right people at the right time and in the right application
- Discovers patterns and trends to harness and exploit data for quicker and better decision making
- Shows how changes in some data affect the other
- Notifies changes to the data — adding or changing attributes
- Ensures data users can access data securely, according to their needs thereby protecting sensitive data
- Allows access to metadata programmatically
Use of data catalog to capture document understanding
Currently, all data catalog products in the market, whether open-source or commercial, are targeted towards structured data. Extending them to manage the unstructured data in documents can bring together information about all data sources together in a single enterprise information repository.
- Discovery: Data catalog products auto-scan metadata in various structured sources for automated discovery and cataloging. But unstructured data need to be manually curated using governed or crowd-sourced curation. For example, a document can be marked with a number for each field to be extracted and then uploaded to the data catalog. This number can then be referenced in the corresponding document and attribute nodes of the data catalog. Such samples act as a training guide to the Quality Control (QC) teams to manually correct the auto-extracted. They also allow machine learning teams to label training data correctly.
- Profile: Data profile is stored in data catalog that defines additional information on attributes like keys, valid values, and rages, the association between attributes across documents, priority between same fields between multiple documents, domain-specific constraints, etc.
- Reuse in multiple use cases: A document and related data can be used for multiple use cases. Data catalog helps in keeping track of fields used in one use case to be reused in others saving time to rework on labeling and extraction.
- Taxonomy: Bank Statement is a type of document. A Bank of America statement is a subtype of a Bank Statement. In a bank statement, there are attributes like the last month’s balance in checking and saving accounts. This hierarchy can be stored in the data catalog and traversed on the UI with drill-down functionality.
- Ontology: A document and fields within a document can have a relationship with other documents or fields in other documents. They can also be associated with business domain glossary, internal structured data, or data from external sources. These relationships can be documented in the data catalog as named links between different types of entities.
- Lineage View: Data catalog visually shows the transformation of data attributes from the first to the last stage of the data analytics pipeline. If the unstructured data sources like documents are managed in the data catalog, this lineage visualization can be extended all the way to the source of truth.
- Analytics View: Data catalog can be used to trace back from analytics view of data. For example, if the monthly amount deposited in the bank and monthly rent received by the owner are used in the calculation of monthly cash flow, this insight can be traced back to the bank statements and rent receipts if these documents are also included in the catalog.
- Application View: Data from documents are used to make decisions using different enterprise applications.For example, the assets and liabilities of an individual are used to approve the loan. The data for all this comes in documents submitted as a part of the loan package. Data catalog allows creating an application view of the data where such rules in the decision engine can be traced back all the way to the source documents.
- Industry Standard View: MISMO in the mortgage industry and FHIR in the healthcare industry are interoperability standards to exchange structured data between various entities. Eventually, the exchange of unstructured documents will give way to the exchange of structured data between disparate systems. For legacy, document-based exchange, this will require converting documents to standard-based structured data in XML or JSON. Data catalog can be used to store this mapping between documents, attributes, and their XPATH or JSON PATH in the corresponding standard. This provides a mapping between the document-centric view of the data to standards-centric view.
- Governance: The access control for specific roles in the organization to specific documents can be mapped in the data catalog. For example, legal documents, contracts, invoices may be accessible to only specific roles in the organization. Data catalog can be used to manage this governance at the document level. Also, access to any “Personally Identifiable Information” in the document can also be managed in the data catalog.
Implementing document management in a data catalog
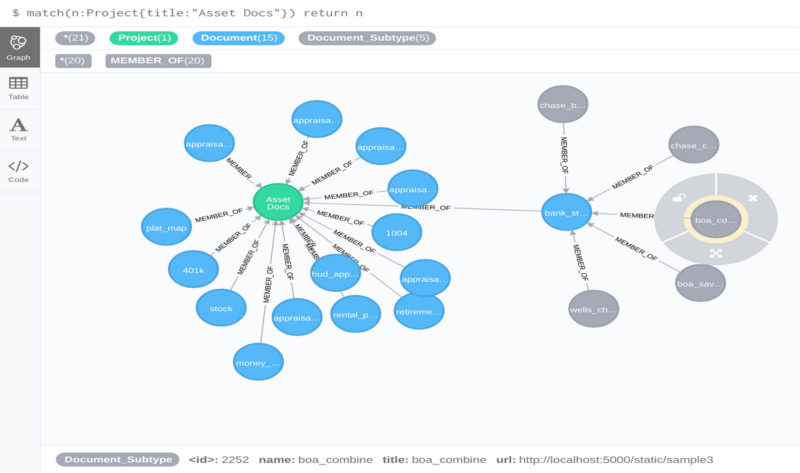
Amundsen is a data discovery and metadata engine for improving the productivity of data analysts, data scientists, and engineers when interacting with data. It does that by indexing data resources (tables, dashboards, streams, etc.) and powering a page-rank style search based on usage patterns (e.g. highly queried tables show up earlier than less queried tables).
We mapped document types, subtypes, and attributes as nodes and relationships in Amundsen. We added an attribute that contains the URL to the document sample with marked fields. This helps in data discovery and visualizing how fields look inside a typical document. There are multiple views that can be queried in Amundsen based on tags.
Use Case View: Which use case is using what documents and attributes
Document View: Types, Subtypes, and fields within each document type
Standards View: MISMO view of fields and their relationship with the document view
Conclusion
The unstructured data in documents is currently being mostly ignored in cataloging due to missing auto-discovery and focus on data catalog. Using a data catalog to manage unstructured data knowledge in documents enriches the enterprise knowledge repository. By assimilating and combining unstructured and structured data information in a common data catalog, organizations would benefit tremendously in bringing structure to their overall analytics effort.


