

In the previous blogs of our series, “The symbiosis between machine learning and blockchain,” we discussed Machine Learning, Blockchain, and the primary use cases of their collaborative functionality.
In part 3 of this series, we will be discussing the drawbacks of centralized machine learning model training and how decentralized model training can overcome them.
We will discuss-
- Challenges of traditional machine learning training.
- What is Federated Learning?
- What is the difference between Federated Learning and Distributed Learning?
- What are the challenges in Federated Learning?
- Integrating Federated Learning and Blockchain.
Challenges of Traditional Machine Learning Training
Machine learning has evolved tremendously in the last decade. Individuals or organizations have attempted to solve numerous problems using this emerging technology. Today, SOTA models are bringing accuracy to the system. However, there are specific challenges with this centralized model training-
- They are highly dependent on the expertise of the organization’s research team.
- They have limited data to train their models and cannot access sensitive data required for model training.
- They have limited computational power and rely on other services that provide GPUs.
These constraints can hinder achieving high accuracy and performance in machine learning models. Here’s how we can use blockchain to overcome these challenges.
Federated Learning
Data privacy has always been a priority for healthcare and finance organizations. Therefore, we must create and train infrastructure in the organization’s local environment without sharing their data externally.
In such cases, we recommend that the data is secured at a single location (storage) and train a model at the exact location. After that, the model is pushed to the service provider’s site. This process applies to all the models trained at disparate locations.
We must note that we push the trained models to a remote site, not the data. These models are then combined to get a generalized metamodel with better outcomes. This concept is Federated Learning which helps in reducing data privacy challenges. Simply put, it is a decentralized way to train machine learning models.
The data owners do not have to rely on centralized organization servers to train the model on their data. The data is within the client’s (who can be individuals, healthcare or military organizations, database providers, etc.) environment. We can use the data procured from devices such as smartphones, edge devices like IoT sensors, or massive databases for training these models.
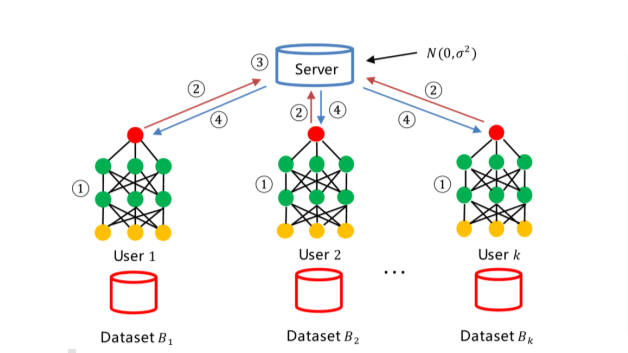
Applications of federated learning include training on-site machine learning models –
- Mobile devices improve text predictions on Google’s Android Keyboard, voice recognition on Google Assistant, and Apple’s Siri.
- Hospital records or EHR documents to get data diversity on diseases.
- Autonomous Self-driving cars make decisions based on the real-time traffic situation.
How Federated learning is different from Distributed learning?
| Sno. | Federated Learning | Distributed Learning |
| 1 | It is a decentralized model training across different nodes. | DL is centralized but parallel model training across different nodes. |
| 2 | Here, data is not distributed. | Data is distributed across different nodes |
| 3 | Data sharing is prohibited | There are no restrictions on data sharing. |
| 4 | Here we use data encryption for data privacy. | No encryption is used. |
The Challenges of Federated Learning
There could be several challenges while implementing Federated Learning Model. Here are a few that I would like to highlight –
- The cost of implementing a decentralized, federated learning system is higher than collecting and processing data in a centralized system.
- An FL system requires data owners to perform model training on their devices which might have low computation power and thus increase the training time.
- There could be a possibility to retrieve sample data from the weights while sending the data model to the service provider. We can secure aggregation of all the models’ weights trained by different participants. The coordinator can only see the aggregate sum and can hardly learn anything from that single participant.
Federated Learning and Blockchain Integration
With the collaborative functionality of federated learning and blockchain, we can unlock the real potential of decentralized machine learning. Blockchain provides participants with an incentive-based system and a sense of security and trust. That encourages other participants to contribute to model training.
Participants can continuously train and update the model on their private data and share the model on the public blockchain. Others can use these models to evaluate predictions on the data.
The participants can use smart contracts to update these models on-chain, that is, within the blockchain environment.
As discussed in the previous blog, there are two main challenges while designing and training a robust and generalized machine learning model: data storage centralization and data privacy and security.
To overcome these, we use blockchain features: decentralization and storage security. We can now create a decentralized system that is powerful, independent of any central organization, scalable, also has data integrity and security.
Now, let’s discuss how leading organizations implement the federated learning concept to create a decentralized model training platform. We can utilize numerous open-source options, but I will recommend OpenMined.
OpenMined
OpenMined is free and open-source software that aims to use federated learning to train and deploy machine learning models while preserving the privacy of the data. Their flagship python libraries are PySyft and PyGrid, which more than 350 contributors developed. Let’s understand how we can use these libraries to implement federated learning.
Recently OpenMined has introduced “Remote Data Science” as the future of private data science, which uses privacy preservation techniques such as privacy-preserving enhancing technologies (PET) to train models remotely on the data in the owner’s environment.
PySyft and PyGrid
PySyft is their main library which uses concepts like Federated Learning, Differential Privacy, Multi-Party Computation, and Homomorphic Encryption to ensure secure and privacy-protected model training on private data within the leading deep learning frameworks like PyTorch and TensorFlow. It provides all the necessary APIs for you to create algorithms that train remotely on confidential data, which can be on the cloud, smartphones, or any edge devices such as IoT sensors.
Whereas, PyGrid provides a peer-to-peer ecosystem for data owners and scientists who can collectively train AI models using APIs from PySyft on decentralized data.
PyGrid consists of three components:
Domain: A Flask-based application that stores private data and models for federated learning and issues instructions to various PyGrid Workers. A single computer or collection of computers can connect to a single Domain node. It is responsible for allowing data owners to manage their private data and providing permissions to the data scientist to perform model training on the data.
Network: A Flask-based application to control, monitor, and route instructions between different PyGrid domains. The network node exists outside of any data owner’s domain. Multiple domains connect to a single network node as per the requirements. The network node provides services such as dataset search, project approval across the domain, etc., through PyGrid.
Worker: An instance managed by a PyGrid Domain used to compute data.
OpenMined can deploy Federated Learning using PySyft and PyGrid in two ways:
- Model-Centric Approach – The main focus is to create a high-quality central model. The data is stored on the users’ end, models are sent to the data source to train on the data, and the updated model is pushed back to the central server.
- Data-Centric Approach – The main focus is to create high-quality data for a particular problem by collaborating similar datasets made available from multiple sources and keeping the training process the same.
Conclusion
In the last two blogs of the series, we learned how blockchain alleviates ML-based applications, including lack of proper data, data privacy and security, and centralized model training. In the next and last blog of the series, we will focus on addressing issues created by limited computational power.
By combining Machine Learning and Blockchain, we can create a powerful and limitless AI application that can solve complex real-time challenges.
Resources
- https://www.analyticsvidhya.com/blog/2021/05/federated-learning-a-beginners-guide/
- https://towardsdatascience.com/decentralized-machine-learning-training-with-federated-learning-c8543696c1e7
- https://www.researchgate.net/publication/341059324_DPFL_a_novel_differentially_private_federated_learning_framework_for_the_unbalanced_data
- https://analyticsindiamag.com/distributed-machine-learning-vs-federated-learning-which-is-better/
- https://blog.openmined.org/remote-data-science-part-1-todays-privacy-challenges-in-bigdata-2/
- https://blog.openmined.org/remote-data-science-part-2-introduction-to-pysyft-and-pygrid/
- https://www.deepbrainchain.org/assets/pdf/DeepBrainChainWhitepaper_en.pdf
- https://www.ravenprotocol.com/


